XJTU-ICS Lab 2: Bomb Lab
前言
Bomb Lab是课程的第二个实验,它给出了一个“炸弹”文件,要求学习者从可执行文件反汇编得到汇编代码,然后通过GDB(GNU Debugger)来知晓“炸弹”的引爆逻辑,并由此给出正确的解决文件solution.txt,正确地拆除全部phase的炸弹。如果成功独立完成了这个实验,相信你对GDB的使用和x86-64汇编语言的理解会上一个台阶。
实验文档与代码框架
实验文档请点击此链接查看。每个人的bomb文件对应的正确答案是不一样的,所以似乎没有公开的代码框架,我仅在此处根据我自己的代码框架给出解法。
原则
如果你是一名正在选修ICS的XJTU的学生,请你务必首先尝试独立解决课程的所有实验,如果实在觉得想不出来了,再参考本文档的解法;非选课人士也可以参考此文档与代码框架,尝试自己完成这些实验。
本文的侧重点
我相信很多同学在这个实验上遇到的困难不在于程序逻辑,而是工具的使用。如果你能完美地记住GDB的各种调试语句,那你的阻力会小很多。所以,我将在本文中总结一些GDB的实用技巧,并从具体的各个phase出发,展示如何使用这一调试工具分析、解决问题。
至于基础知识,我也会讲到一些最核心的部分,只不过可能不会非常细致,因为这些知识本应该从书本和课程中掌握,而不是一个实验解析应该负责的部分。
参考实现
本人的实验代码会同步到这一仓库,读者可以自行拉取到本地参考。但是,请一定要阅读仓库的README文件,坚持独立完成实验,不要抄袭。独立完成实验对于你的实际能力提升有很大帮助。
实验内容与基本要求
基本任务
这个实验给出了一个6阶段的“炸弹”文件bomb,并且给出了基本的代码框架bomb.c。你需要根据可执行文件对应的汇编代码来获知代码的逻辑,获取能够成功拆弹的答案,并填到solution.txt中。
Tip
实验并没有给出原始的汇编代码,gdb会在调试的时候自动调用内置的反汇编库获得该可执行程序的汇编代码,你也可以手动调用GNU的objdump工具来获取汇编代码文件。
这6个phase实际上就是6个函数,读取你输入的内容作为参数,每个phase的答案都是唯一的。只有你输入了正确的答案,才不会在当前阶段引爆炸弹。
注意事项
- 请你将你的答案分行写在
solution.txt文件中,每一行对应一个phase的答案,多个变量中间用空格分隔; - 如果答案包含字符串,不要用双引号包裹,直接敲入文件就可以。
- 输入完最后一个phase的答案后,请再留出一个空行,避免
EOF标志被误认为被输进程序中的字符。
辅助内容
在阅读这一节之前,读者不妨先参考课程文档以及其给出的各种辅助资料,以下给出的内容可以作为补充参考。
⚠️CS107 x86-64 Reference Sheet
这是Stanford CS107课程Computer Organization & Systems的一份参考资料,使用的教材也是CSAPP。这份Sheet比较全面地总结了常用的x86-64汇编指令、条件码的设置条件、以及各个通用寄存器约定俗成的用途等内容,非常有用。
可以通过CS107官网或者本课程官网获取:CS107官网链接 XJTU-ICS托管资源 本网站托管资源
ASCII码对照表
无需多言此表的重要性,而这部分内容在后面解题的时候会用到。可以很轻易地从网上获取到这个对照表,在此给出一个版本,本站托管文件在此。
GDB常用命令
怎么开始?
在正式进入单步调试前,你还有很多指令要敲,下例给出开始调试时用到的几个必要的命令:
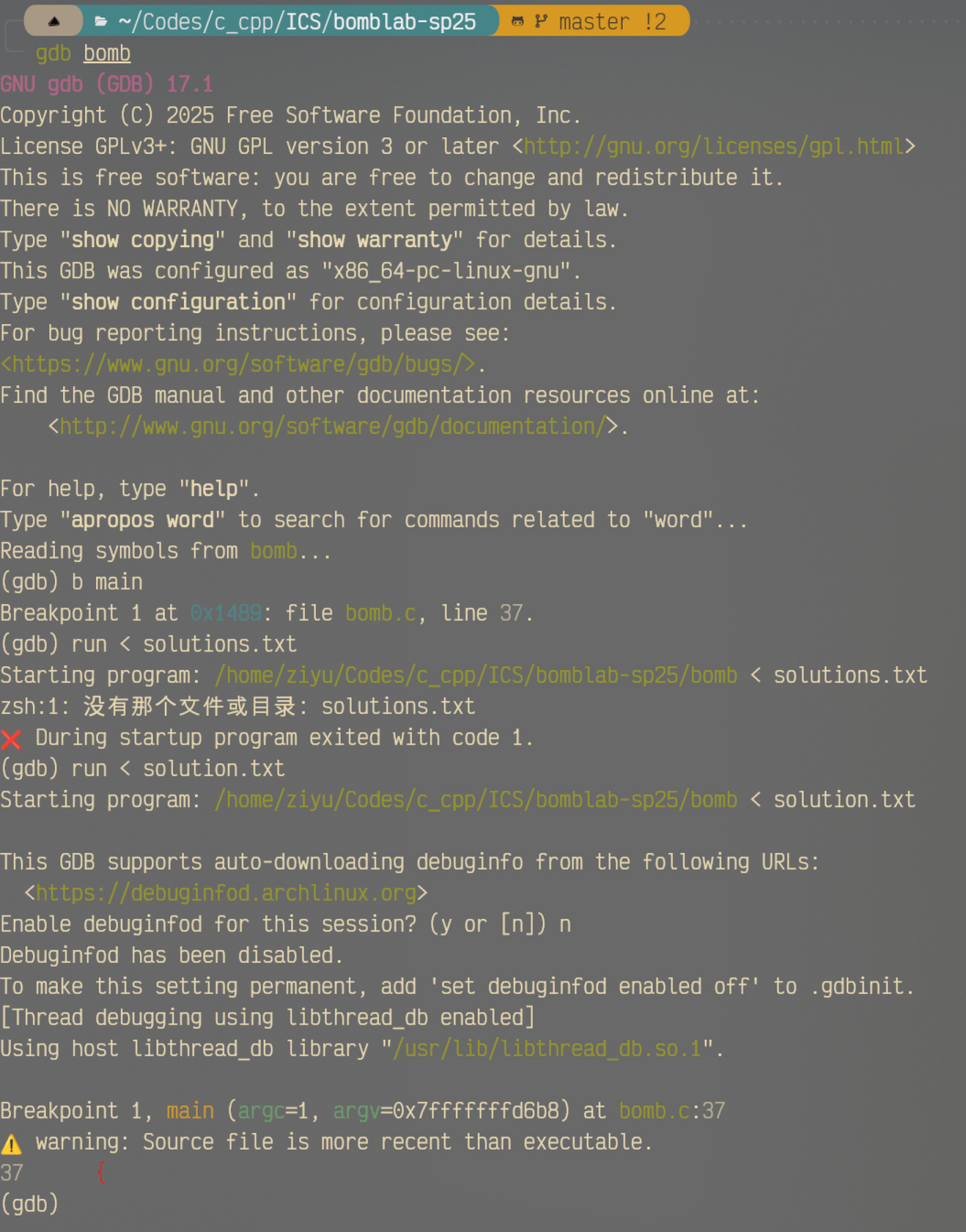
b main:也就是break main,在main函数的入口处打断点,从而能够让调试进行;也可以在某个特定地址处设断点,如b 0xffffffffinfo break:查看所有断点信息;delete [n]:删除第n个断点,n值可以通过info break获取;continue:继续执行直到下一个断点;debuginfod:作用就是记录你的调试信息,一般来说不需要,也不用在意;run < solution.txt:run是开始调试的指令,利用<这一符号来输入solution.txt。
接下来就可以进行具体的调试操作了。
步进/步过
在GDB中,常用的步进(Step In)/步过(Step Over)操作由指令来实现,分为源代码层级和机器指令层级(也就是汇编)。具体指令如下:
| 维度 | Step In (进入函数内部) | Step Over (跳过函数调用) |
|---|---|---|
| 源代码层级 (C 代码) | step /s |
next /n |
| 机器指令层级 (汇编) | stepi/si |
nexti/ni |
由于我们这里主要根据汇编代码来分析程序,所以肯定是用ni和si最多。
观察不同类型的值
我们主要通过 print/p (简写)和 examine/x (简写)来获取我们想要看到的数据。二者的区别在于p操作是仅仅查看存储单元所存之 值本身 ,而x操作是把存储单元存储的值当作地址,读取这个 地址对应的内存中存放的值 。可以将后者当成一种 指针解引用 的操作。
既然是展示值,那么必然要涉及到以什么格式展示这个值。
x操作
examine指令的完整语法是x / <n> <f> <u> addr,这三个参数分别为
-
<n>:显示单位的数量,比如x/4可以表示查看连续的4个内存单元; -
<f>:显示的格式,和C语言的转义字符规定有相同之处参数 含义 常用场景 xHexadecimal (十六进制) 查看该地址指向的内存单元存储的原始十六进制数值。 sString (字符串) 自动读取内存直到遇到 \0为止。iInstruction (汇编指令) 查看该内存地址存储的机器码对应的汇编指令。 dDecimal (十进制) 查看普通的整数变量。 uUnsigned decimal (无符号十进制) 查看无符号整数。 tBinary (二进制) 查看具体的位(Bit)状态(t 代表 two)。 cChar (字符) 查看单个字符。 -
<u>:单元大小,指定你要查看的一个单元占多少字节。参数 含义 字节数 对应 C 类型 bByte 1 字节 charhHalfword 2 字节 shortwWord 4 字节 int/floatgGiant word 8 字节 x86-64 指针 / long在格式参数处选择
s的时候,这里就不需指定了,因为字符串是默认读取到\0结束的。
p操作
p 指令的参数只有格式(Format),没有数量(Number)和单位(Unit): p /<f> <expression>,它的功能比较简单,一次只支持看一个值,单位大小也不支持指定,而是由表达式的具体类型决定,比如一个寄存器%rax就是8字节,因此就会展示8字节的数据。
| 格式参数 | 全称 | 显示内容 | 炸弹实验场景 |
|---|---|---|---|
| /x | Hexadecimal | 十六进制。显示最原始的数值。 | 看内存地址、看寄存器值。 |
| /d | Decimal | 有符号十进制。 | 看普通的整数比较(如 cmp $0x5, %eax)。 |
| /u | Unsigned | 无符号十进制。 | 当处理很大的正数,或者不希望看到负号时使用。 |
| /t | Two (Binary) | 二进制。显示 0 和 1。 | 查看标志位或进行位运算(AND/OR/XOR)调试。 |
| /c | Char | 字符。按照 ASCII 码翻译。 | 查看寄存器里存的是不是某个特定字符(如 ‘A’)。 |
| /a | Address | 地址模式。 | 它会尝试告诉你这个地址属于哪个函数(如 0x401234 <main+20>)。 |
| /f | Float | 浮点数。 | 查看浮点运算寄存器的值。 |
display命令
这个命令可以在每次程序执行完一步后都打印出你指定的内存单元的值,它兼容p/x指令的参数形式,因此按照给出的参数不同,有可能展示存放的值(地址)本身,也可能展示地址对应的单元的值。
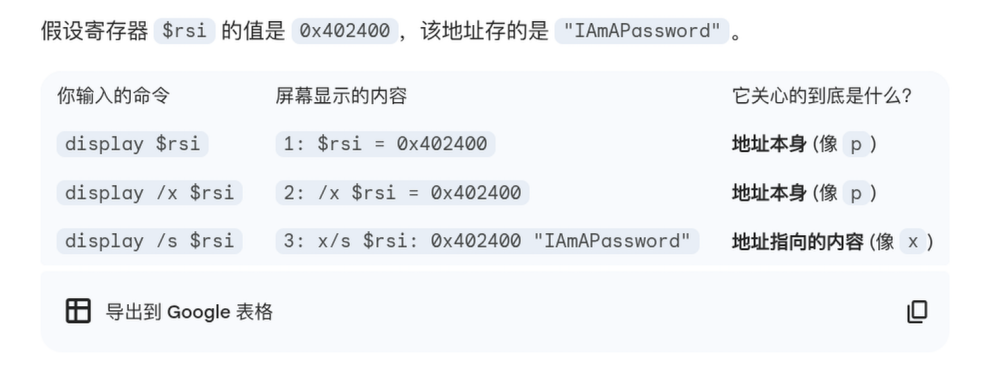
下图是一个示例,可以验证以上Gemini的说法:
寄存器信息查询
使用info reg命令,查看所有寄存器的值。
倒退操作
在GDB中,如果不特意设置,只能单向调试,而不能在遇到问题时倒回来。如果要倒退,那就要开启record模式。
record也分为不同的方式。一种是默认的full全记录模式,需要在执行run命令之前先输入target record-full。但是由于record要保存寄存器快照、内存变更日志以及指令序列等信息,会导致调试的空间效率和时间效率大大降低,所以不建议开启full模式。
更好的方法是,在调试的过程中,遇到你觉得可能需要记录的地方时,输入record命令,开始记录;在通过某个需要用到倒退功能的片段后,及时使用record stop命令清空内存日志。
下面将常用命令在表格中总结:
| 命令 | 缩写 | 含义 |
|---|---|---|
target record-full |
略 | |
record |
略 | |
record stop |
略 | |
reverse-stepi <N> |
rsi <N> |
反向步进(N步) |
reverse-nexti <N> |
rni <N> |
反向步过(N步) |
reverse-continue |
rc |
回退到上一个断点 |
set record instruction-history-size <N>/unlimited |
设置缓冲区容纳的最大指令条数为N条/无限 |
下例给出一个实际应用:
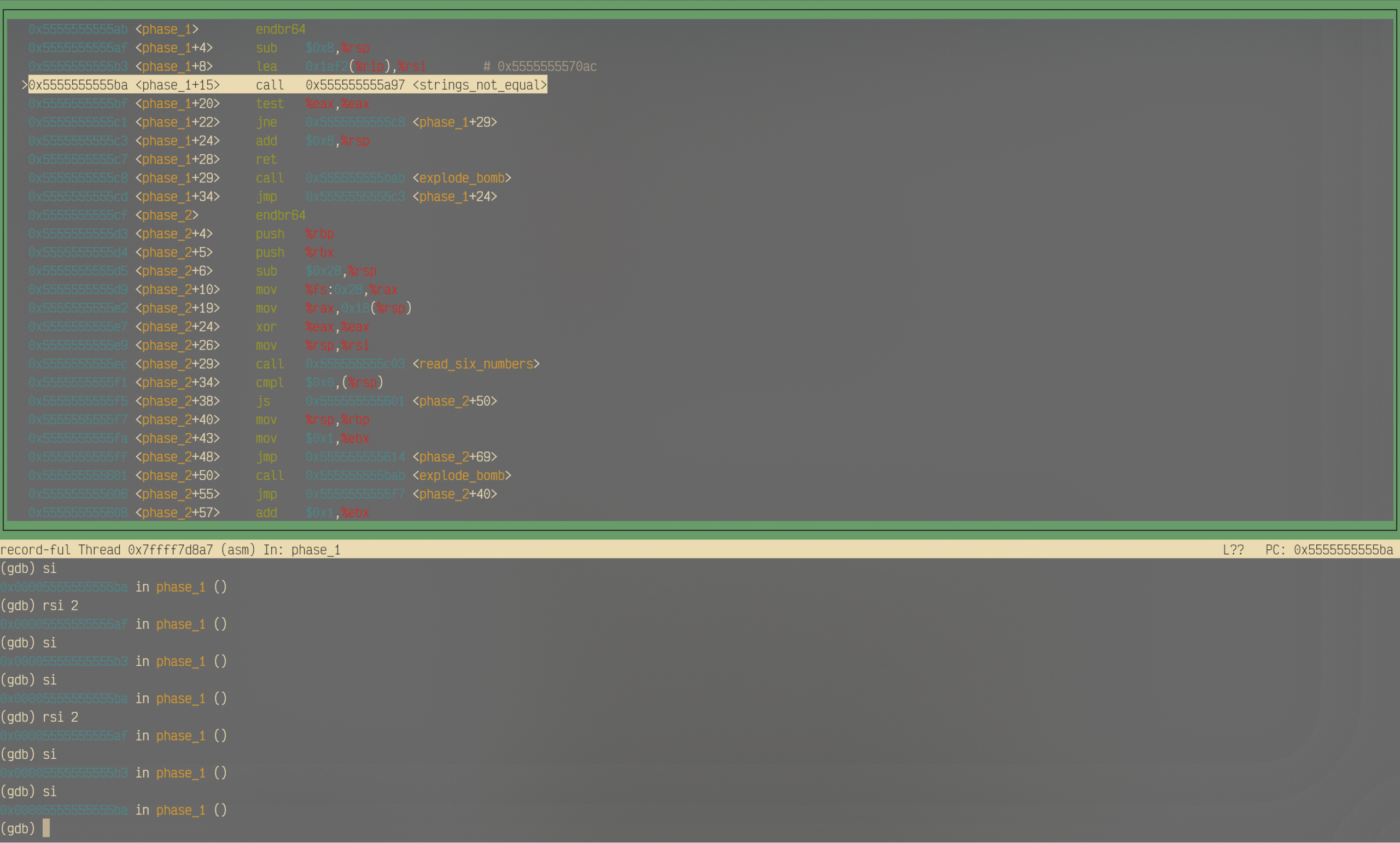
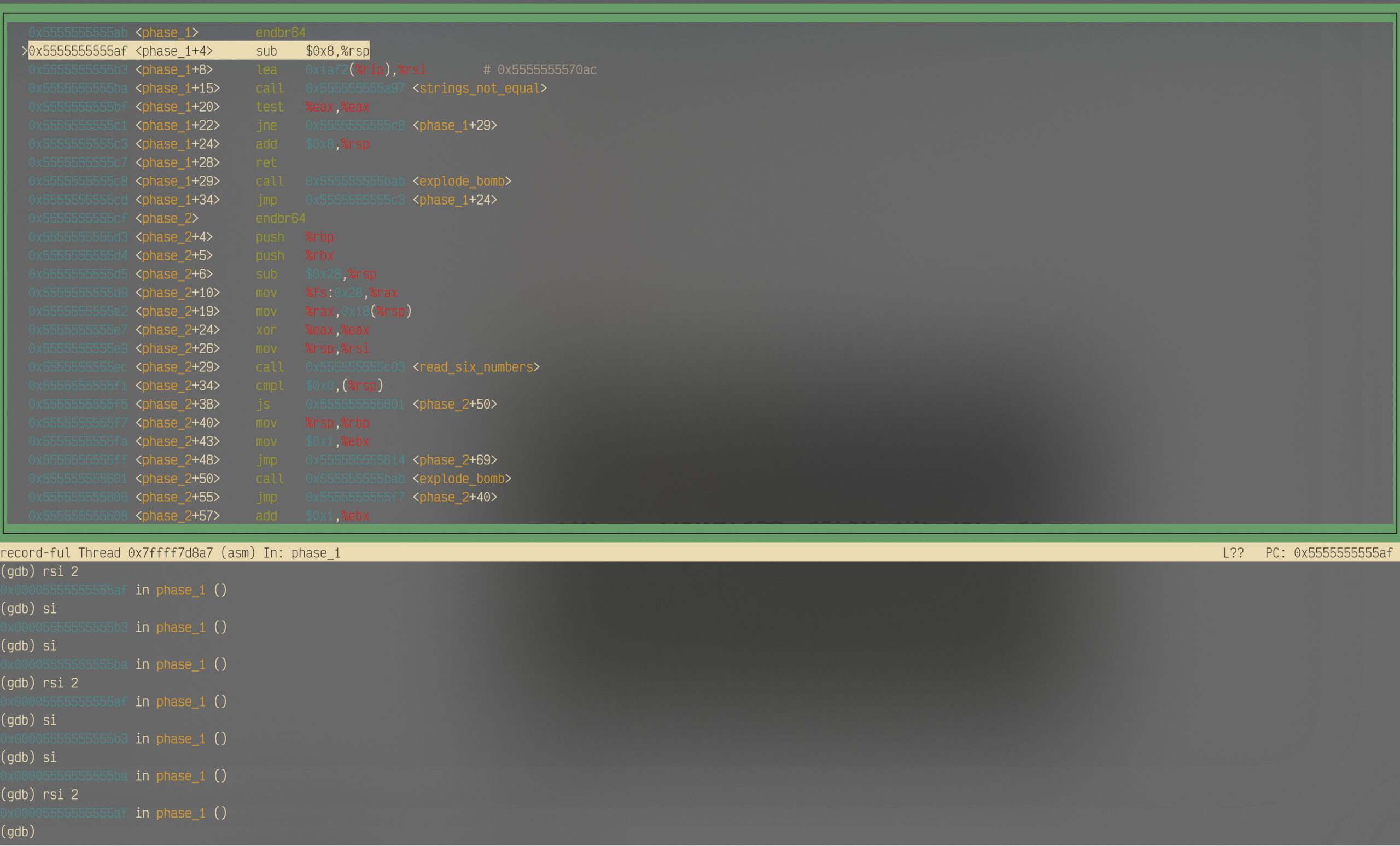
可以看到,在执行了
rsi 2之后,立刻回到了两条汇编指令之前。
⚠️TUI模式
TUI (Text User Interface) 是 GDB 的“分屏增强模式”。它支持你在单步调试的时候边看代码边调试,还能监视各种寄存器的值。这是非常关键的一个功能,能够让调试方便许多,让你从频繁的x/i $rip操作中解脱出来。
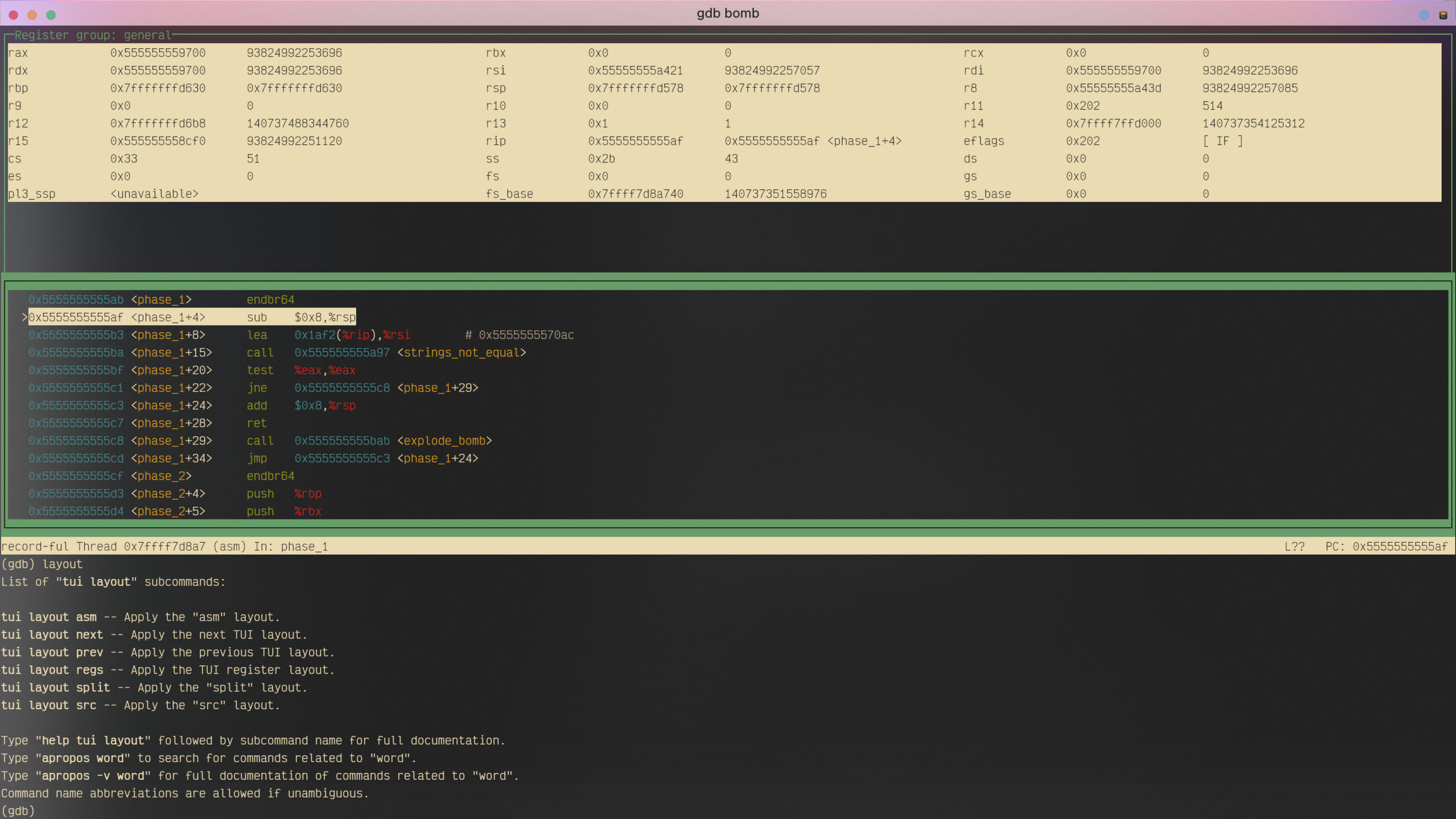
你可以在开始调试时随时通过Ctrl + X + A来进入/退出TUI模式,然后输入layout asm调取汇编代码界面,layout regs调取寄存器窗口(寄存器数值变动的时候会高亮)。
但是,注意这个时候你可能没法使用键盘的Up Down来调取上一个输入的命令,也没法用鼠标选中文字了,因为此时默认你的“焦点(Focus)”是在代码窗口上的,所以上/下键就用来滚动浏览汇编代码了,鼠标也没法直接选中终端文字了。这个时候你可以使用Ctrl + P/N来代替Up/Down方向键,可以按住Shift同时使用鼠标选中文字复制/粘贴。又或者你可以直接输入focus cmd将焦点转回到命令行,在使用完之后再输入focus asm切换回代码窗口。
下表总结可能常用到的TUI模式下的操作:
| 类别 | 命令 / 快捷键 | 作用描述 |
|---|---|---|
| 模式切换 | Ctrl + X + A |
开关 TUI |
layout asm |
显示汇编 | |
layout regs |
在上方开启寄存器窗口,数值变化会变红。 | |
layout src |
显示源码 | |
layout split |
分屏,同时显示源码和汇编。 | |
| 窗口焦点 | focus cmd |
控制权给命令行:恢复方向键调取历史命令的功能。 |
focus asm |
控制权给汇编:方向键变为滚动查看代码。 | |
Ctrl + X + O |
循环切换焦点:在已打开的窗口间轮转焦点。 | |
| 命令导航 | Ctrl + P |
等同于“上方向键” |
Ctrl + N |
等同于“下方向键”。 | |
| 显示修复 | Ctrl + L |
刷新屏幕:当程序输出导致花屏时,刷新修复。 |
| 高效操作 | Ctrl + X + S |
单键模式:按 n 为next,按 s 为step,按c为continue。 |
winheight asm +5 |
调整高度:给汇编窗口增加 5 行高度。 | |
| 终端模拟器处理鼠标事件 | Shift + 鼠标操作 |
临时使用鼠标完成某些操作。 |
题解
源代码
1 | /*************************************************************************** |
程序的注释很有意思,感兴趣的读者可以读一读,开头的许可证的中文翻译如下:
邪恶博士的阴险炸弹,版本 1.1
版权所有 2011,邪恶博士有限公司。保留所有权利。
许可证:
邪恶博士有限公司(以下简称 作恶者)在此授予您(以下简称 受害者)使用此炸弹(以下简称 本炸弹)的明确许可。这是一种有限期的许可证,将在 受害者 死亡时过期。
作恶者 对因本程序造成的损害、挫败、精神失常、金鱼眼(bug-eyes)、腕管综合征、失眠或其他对 受害者 的伤害概不负责。除非 作恶者 想要揽功,那是另一回事。
受害者 不得将本炸弹的源代码分发给 作恶者 的任何敌人。任何 受害者 均不得对本程序进行调试、逆向工程、运行 “strings” 命令、反编译、解密,或使用任何其他技术来获取本炸弹的相关知识或拆除本炸弹。
在处理本程序时,不得穿着防爆服。
作恶者 不会为他那拙劣的幽默感道歉。
在法律禁止本炸弹的地区,本许可证无效。
汇编代码
这里我们使用objdump -d bomb > bomb.s来生成汇编语言文件。整个汇编代码很长,我们会在下面结合它来分析各个phase的程序逻辑。
phase_1:字符串比较
1 | 14e0: e8 63 07 00 00 call 1c48 <read_line> |
快速解题
如果要一步一步查看过程中的所有代码,一定会很麻烦。不妨跳过strings_not_equal的代码细节,将它当成一个“黑盒”,这样就简单得多。从字面意义上推测,这个函数有可能是一个判断器。我们不妨假设:如果送进去的特定数量的字符串内容相同,就返回0(False);不相同则返回1(True)。
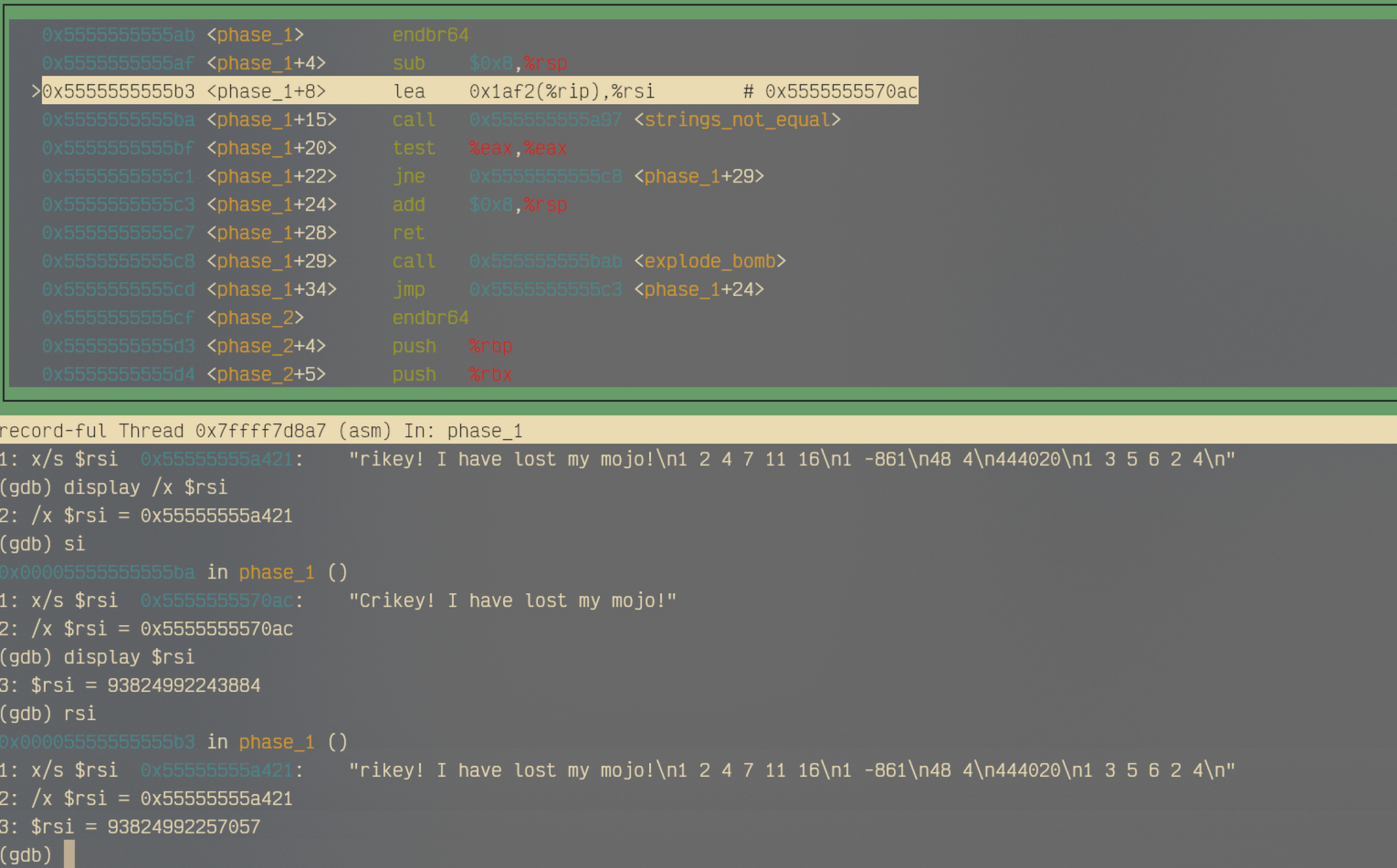
分析strings_not_equal的入参,我们首先可以看到,首参%rdi在main函数调用phase_1之前被设置好了,内容就是第一行输入(14e5);而调用前的lea指令把一个地址加载到了第二参数寄存器%rsi中,所以我们可以推测出,这个函数总共接收两个参数。那么这个函数的作用有可能就是判断输入的字符串是否与程序中内置的字符串相等。而%ax寄存器存放的是函数的返回值,假设这个函数返回布尔值或者1/0来表示,那么只要两个字符串不相等——返回值为1——test指令检测出返回值不为0——就会跳转到15c8引爆炸弹。所以只需要在调试的时候找到%rsi存储的地址处的字符串内容,并填到输入文本的第一行,就解决了。
实际操作
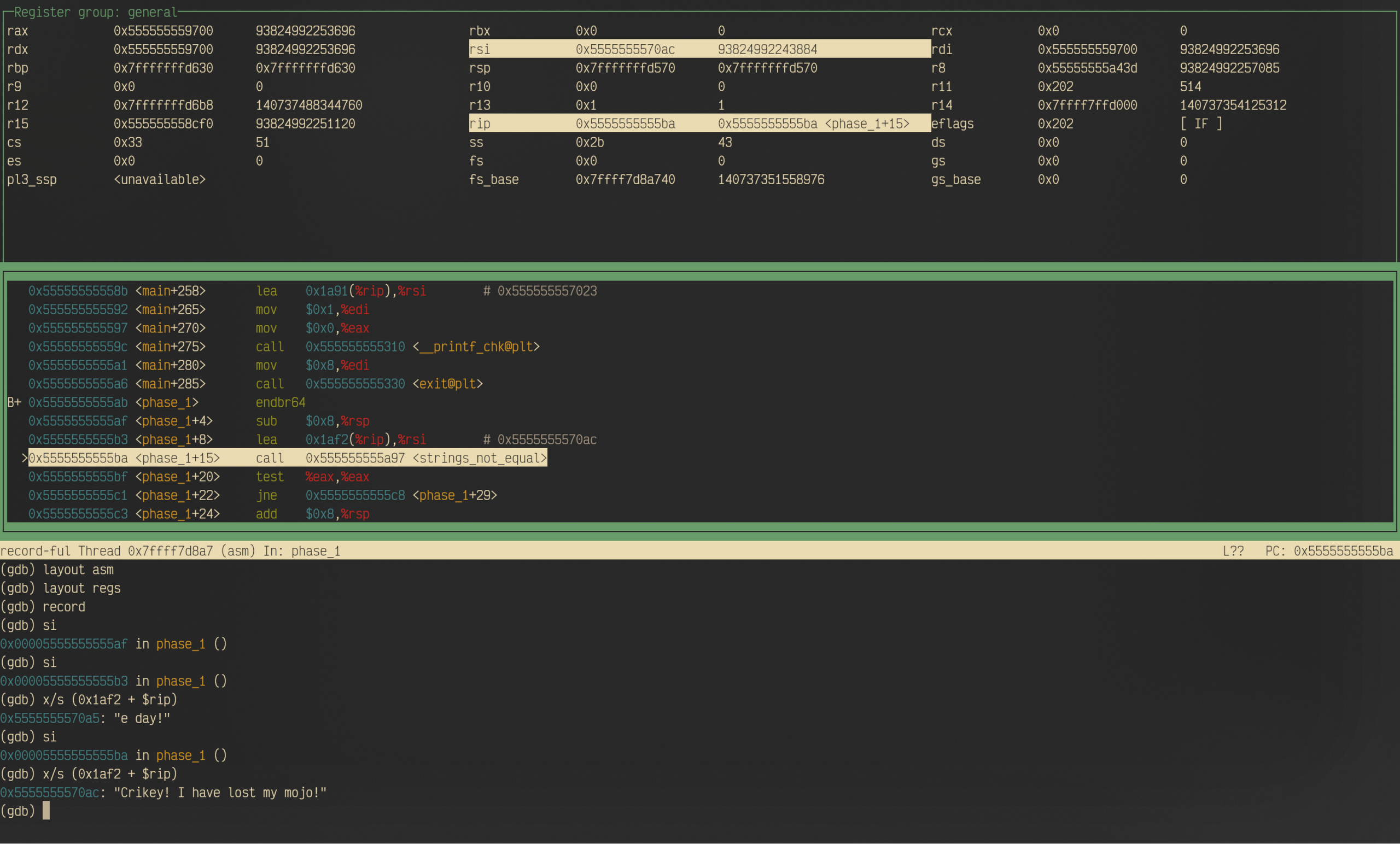
我们通过调试,获得了传入函数strings_not_equal的第二参数,是字符串Crikey! I have lost my mojo!。把它输入到solution.txt中,就能成功拆除phase_1的炸弹。
知识补充
-
栈管理
如果观察这一段汇编代码的结构,我们可以发现,
sub $0x8,%rsp和add $0x8,%rsp这两句是一个函数调用过程中标准的栈管理指令。由于在x86-64架构中,Stack是向低地址增长的,所以sub的作用是申请8字节的临时空间,用于对齐栈顶或者存放局部变量;而add就是在函数执行结束前收回栈帧(“销毁”空间), 恢复栈指针原位,维持栈平衡。最后ret指令弹出当前%rsp指向位置的值,将值加载到%rip中(%rsp存储的这个值通常是下一条指令的地址,call指令提前将它压入此处),回到调用前的状态。 -
lea指令lea 0x1af2(%rip),%rsi这句指令有一个逻辑上的细节。如果在这条指令执行之前,直接按照这个偏移量来获取字符串,那是无法找到正确答案的。实际上,这是因为(0x1af2 + %rip) -> %rsi是发生在PC <- (PC) + 1这个步骤之后的。这个问题涉及到了一个很关键的知识点,它在计算机组成原理课程中也会被进一步介绍。简单来说,现在CPU通常采用五级流水线架构,也就是一条指令分为五个阶段:“取指——译码——执行——访存——写回”。程序计数器自动增加一个指令长度的环节发生在取指阶段,也就是说
%rip自动累加这个操作在这阶段已经完成;而真正实现计算0x1af2 + %rip这个加法是在执行阶段。所以,
%rip的值需要先增加一个指令的长度,然后再和这个偏移量相加,放到%rsi上。而x86-64采用的是CISC架构,使用的是变长指令集,因此每个指令的长度是不一样的,所以最好要在这个指令执行完之后再使用x指令获取字符串,或者直接查看%rsi的值,要不然就要在这个指令执行前使用x/s ($rip + 0x1af2 + 0x7)来获取字符串,因为lea的长度是7字节。 -
test指令test指令会将两个操作数按位相与,然后根据结果设置标志位。而eax/rax又是约定俗成的存储返回值的寄存器。这就意味着,如果假设strings_not_equal返回一个布尔值/int值1/0到%eax中,代表“两字符串不相等”这一判断的真假;1是两个字符串不相同,0是两个字符串相同。那么若%eax不为0,ZF将不会被置1,于是%rip就会跳转到15c8,“炸弹”爆炸,拆弹失败。这就印证了我们的猜想:一定要让传入的字符串和程序中存储的字符串相同。
phase_2:数列找规律
1 | 00000000000015cf <phase_2>: |
快速解题
这道题一上来,我们就可以看到read_six_numbers,所以我们姑且认为需要输入的就是6个数字。我们仍然不纠结read_six_numbers的细节,直接看主框架。
在调用完这个函数后,后面跟了一个比较语句cmpl $0x0,(%rsp)和一个判断语句js 1601 <phase_2+0x32>,也就是说:如果(%rsp)小于0,那就直接爆炸。那么(%rsp)里面是什么值呢?我们通过调试得出(见下图),read_six_numbers得到的第一个数字就存放在%rsp处,往后按照顺序每4个字节存放一个数字,总共六个数字。4字节的大小正好对应int类型占用的字节数。
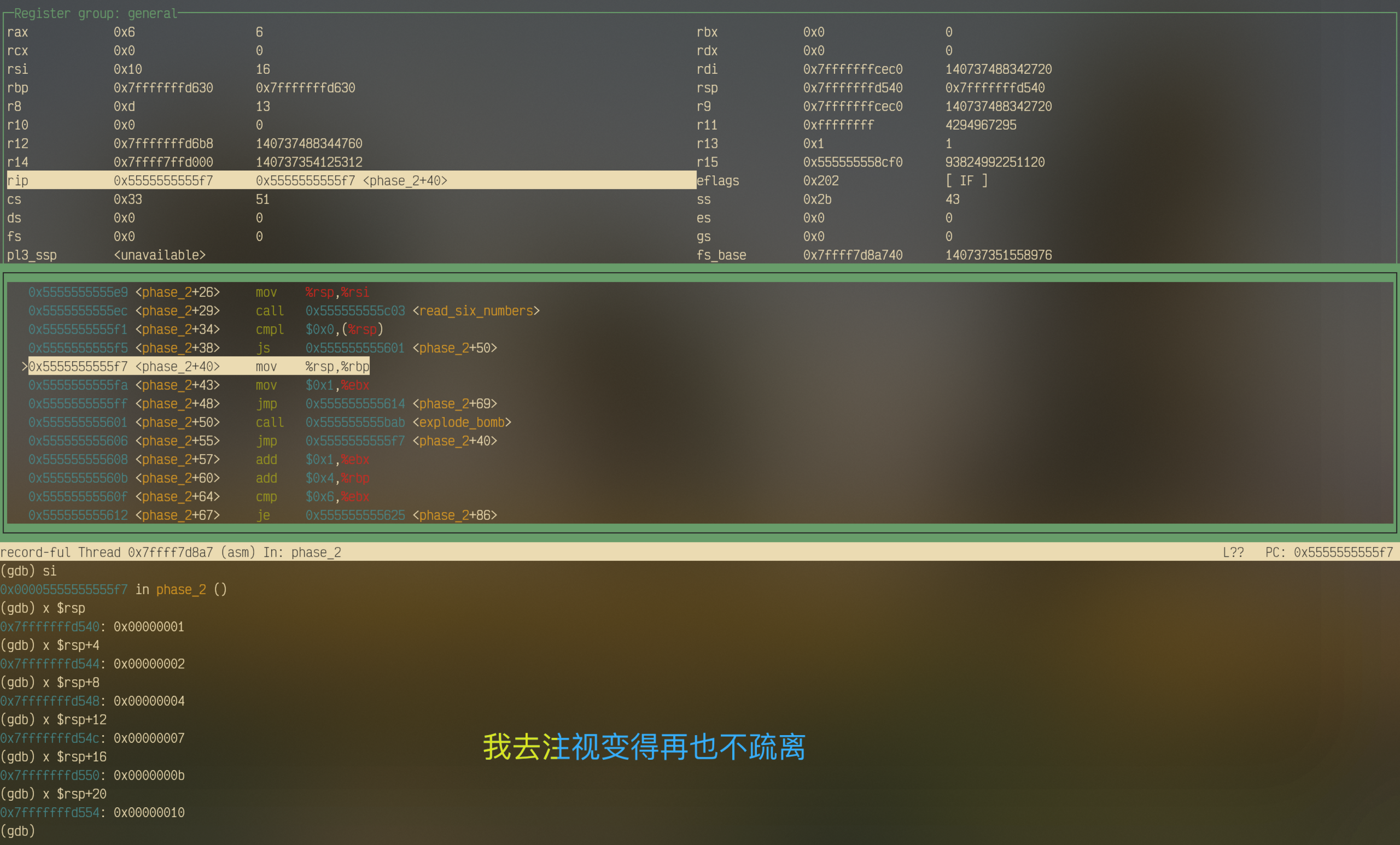
所以得到第一个结论:第一个数字需要是非负(整)数。
Note
read_six_numbers的细节会放在下面讲解。- 关于
cmpl和js指令,请参考前文提到的Reference Sheet。 - 因为本章学习内容根本不涉及浮点数,我们的lab也不会涉及到浮点类型的数据,浮点数的内容可以找到CSAPP原书对应的部分阅读学习。
接着看,后面的代码把六个数字的起始地址放到了%rbp中,然后%ebx寄存器被初始化为1 。以下跳转到1614处,程序先给第一个数字加上%ebx,然后让它和后一个数字比较。如果不相等,就会爆炸;如果相等,就会让%ebx+1 ,%rbp向后4字节,也就是继续检查第二个数字。下面对第二个数字的操作也是相同的:先加上%ebx,然后和后一个数字比较,相等则%ebx继续自增1。直到%ebx为6的时候,证明第五个数字加上当时的%ebx(值为5)与第六个数字也相等,由此跳出循环,拆弹成功。
所以我们可以得到第二个结论:输入的数列必须满足以下规律:
- ;
所以一个可能的答案为:1 2 4 7 11 16。当然,开头数字可以是任意非负数,所以答案不唯一。
知识补充
read_six_numbers解析
1 | 0000000000001c03 <read_six_numbers>: |
这个函数中最难读懂的是关于sscanf函数的汇编指令。
sscanf的详细介绍可以通过man命令查询,或者更好的方法是向现在发达的大语言模型发问。以下是执行man sscanf命令查询后的部分介绍文字,它的作用可以被简单概括为:按照format的规则处理输入的str,处理的结果存放在后面的参数里;返回值是成功处理的元素的数量。
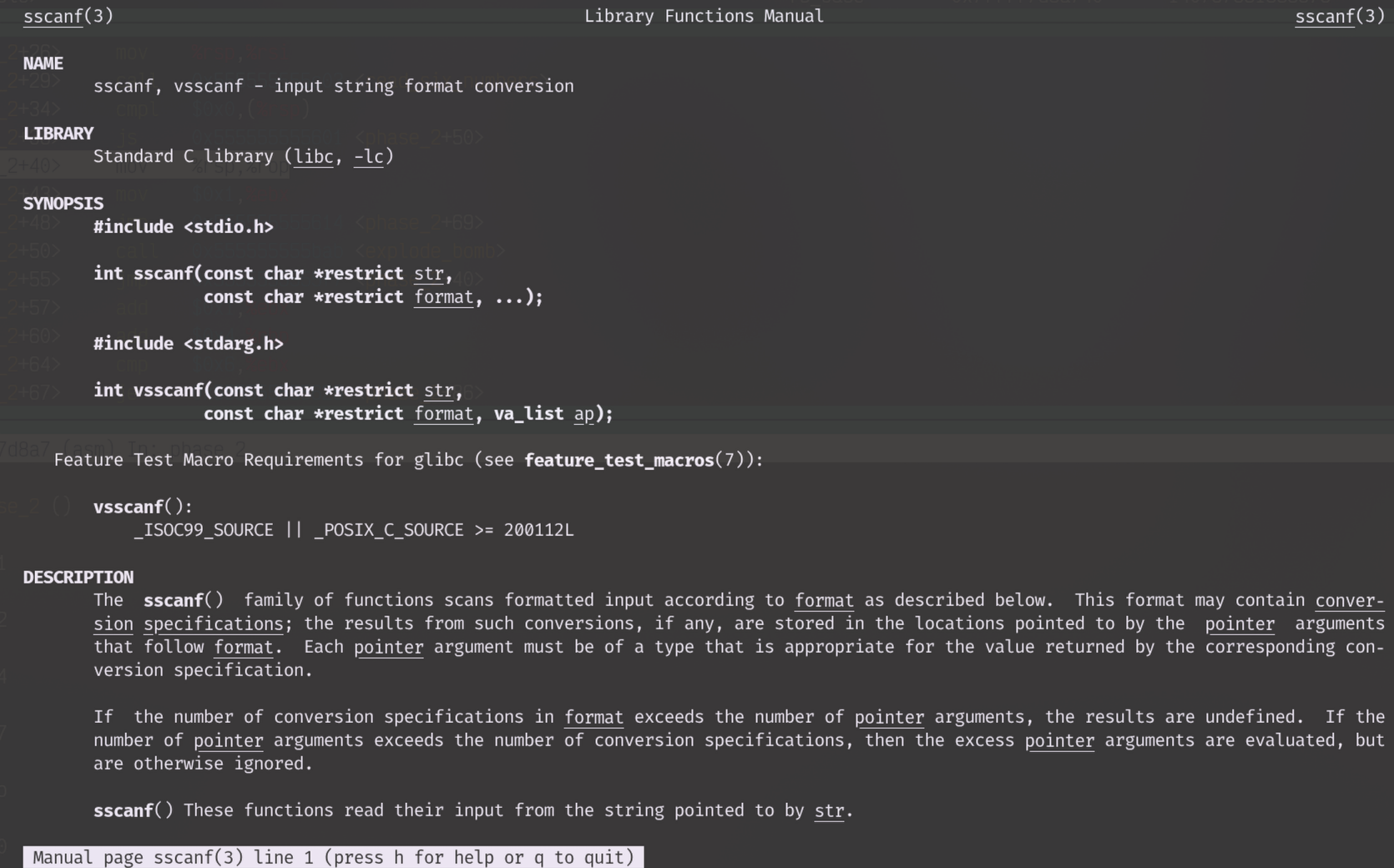

而从main函数中,我们可以知道,%rdi就是我们输入的承载六个数字的字符串起始地址;二参数是格式化字符串,这个可以不深究;后面的参数,我们推测是存放六个数字的地址。所以,根据汇编代码总结一下,传参情况如下表所示:
| 参数序号 | 寄存器 | sscanf 中对应的含义 |
|---|---|---|
| 第1个 | %rdi |
输入字符串(六个数字) |
| 第2个 | %rsi |
格式字符串 0x1701(%rip),%rsi |
| 第3个 | %rdx |
&num[0] → (%rsp) |
| 第4个 | %rcx |
&num[1] → 4(%rsp) |
| 第5个 | %r8 |
&num[2] → 8(%rsp) |
| 第6个 | %r9 |
&num[3] → 0xc(%rsp) |
| 第7个 | 栈上 push | &num[4] → 0x10(%rsp) |
| 第8个 | 栈上 push | &num[5] → 0x14(%rsp) |
前6个参数走寄存器,超过6个的参数通过压栈传递。
这样,一切就说得通了。执行完sscanf命令后,我们检查返回值%eax,如果小于等于5,直接爆炸。所以输入的数字数量应该不小于6个。
phase_3:switch语句
1 | 0000000000001641 <phase_3>: |
快速解题
关于本题,课程文档给出的提示如下:
1 | switch () |
这倒是给了我们灵感,我们可以在汇编代码中寻找类似switch & case语句的逻辑。
首先我们发现了在上一个phase就出现过的sscanf语句,发现它的三参和四参是(%rsp)和(%rsp) + 4,除此之外没有压栈的操作,然后我们继续,看到函数返回后,首先检验%eax是否大于1 ,如果否,则炸弹直接爆炸。这或许提示我们需要输入两个元素,它们被存储的地址从%rsp开始。
然后继续向下,我们发现了1672的cmpl语句和后面的ja,这说明第一个数字不能超过7,并且不能为负数,否则就会爆炸。这是不是很像switch的各种case和default?
Note
为什么不能是负数,这个限定是ja指令规定的,下面知识补充部分会详细解释。
向下,我们发现程序将一个预留的地址放到了%rdx中,把首参放到了%rax,然后用一个表达式求出了一个地址,把这个地址放到%rax中,其值为(SignExt(M[%rdx + 4 * %rax])) + %rdx。接下来直接跳转到这个地址处。
Note
movslq命令似乎在Reference Sheet里没有特别说明,需要结合课上学到的内容来理解,实际上就是把32位数据符号拓展到64位。见下面的知识补充部分。
而我们不难发现,以上运算中,唯一的变数就是%rax,你输入的首参是多少,那么跳转的地址就有几个4字节的偏移量。
下面以首参为1为例。
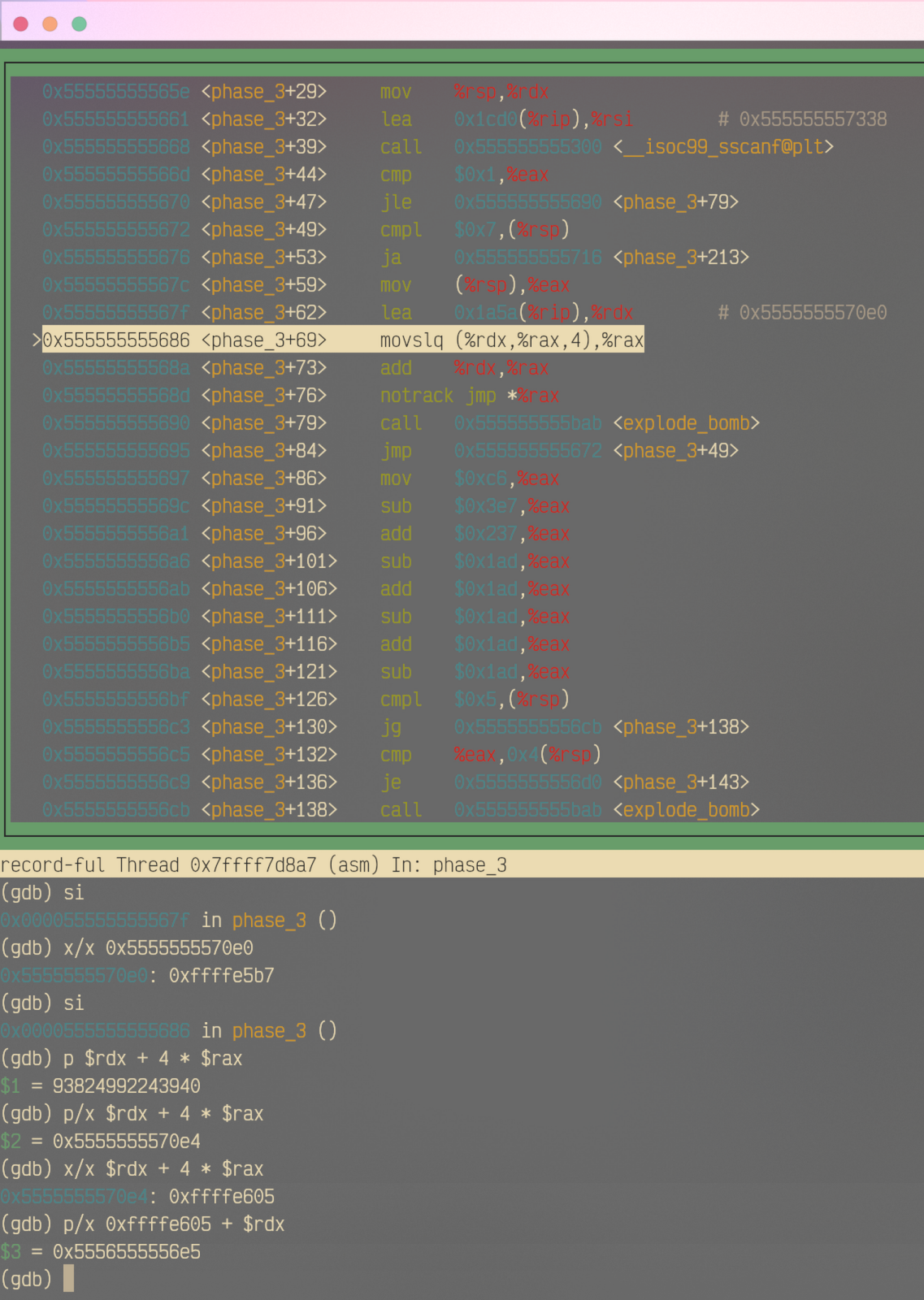
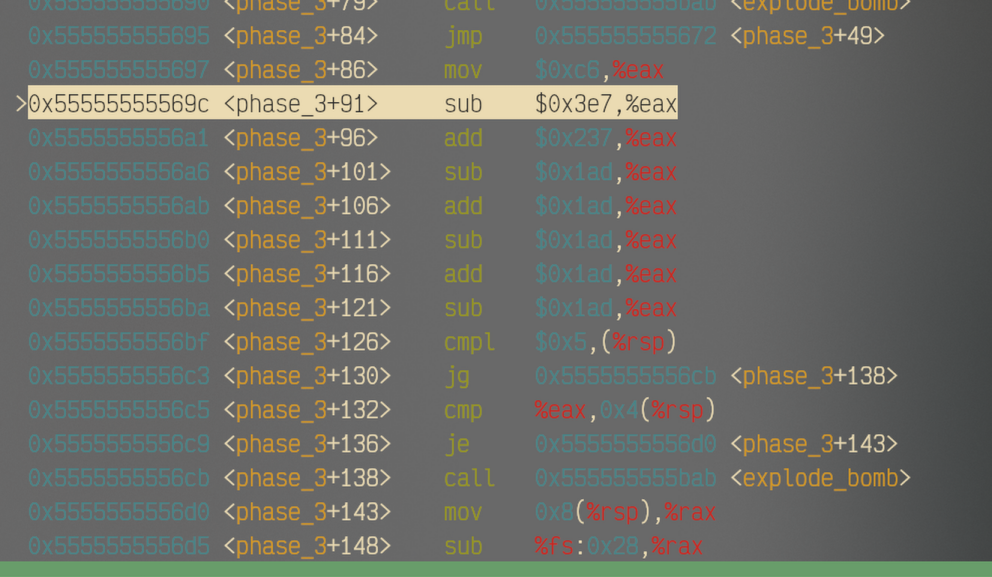
Note
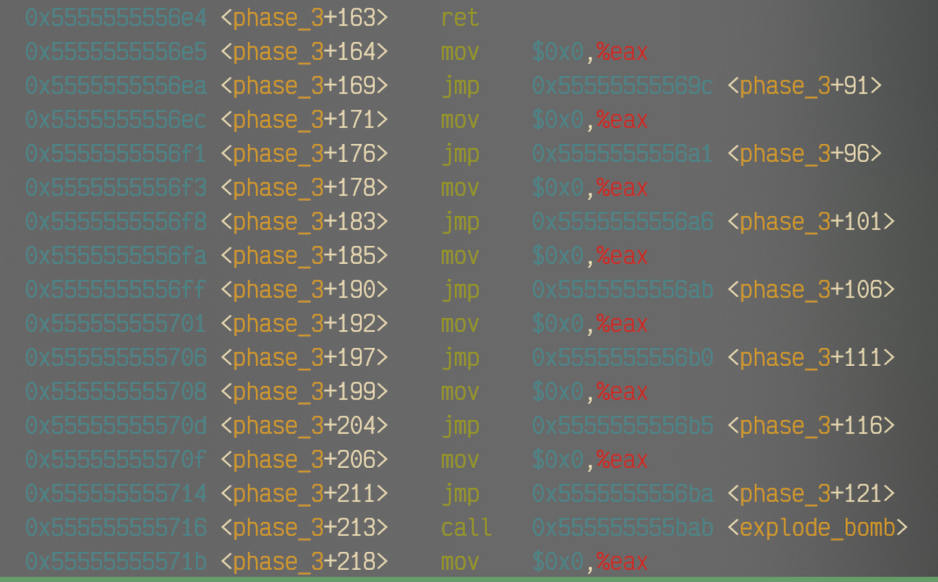
可以看到,原本存放在%rdx的预留地址是0x5555555570e0。上例中输入的首参是1,所以对应的movslq得到的地址中的值就是0xffffe605,这个结果和预留地址相加,结果是0x5556555556e5,就是<phase_3+163>的ret后第一个mov操作。下面每个mov操作后面都对应不同的跳转地址,按照我们目前的选择,就跳转到了图中这个位置。
按照首参正确跳转后,做了一系列加减运算,这都不重要。关键是下面两个比较语句cmpl cmp。第一个cmpl要检查(%rsp)是否大于5,如果大于就会引爆炸弹;第二个比较语句比较最后的运算结果是否与二参相等,如果相等才能退出;否则就会爆炸。
所以我们总结最后的逻辑如下(以类C语言代码形式呈现):
1 | if (sscanf(input, "%d %d", &first, &second) <= 1) explode; |
而我输入的首参是1 ,对应的f1()的返回值是-861。所以最后需要输入的答案:
1 -861
解决!
知识补充
跳转操作
若想搞清楚各种跳转操作,需要仔细回顾课内所学,并阅读Reference Sheet。下面我截取课件和Sheet中和跳转内容有关的内容,据此总结跳转操作的问题。

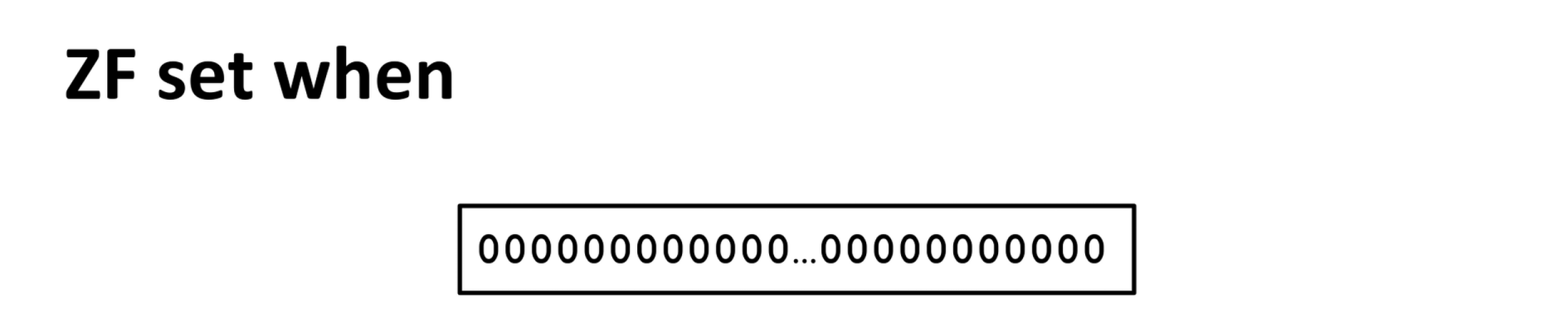

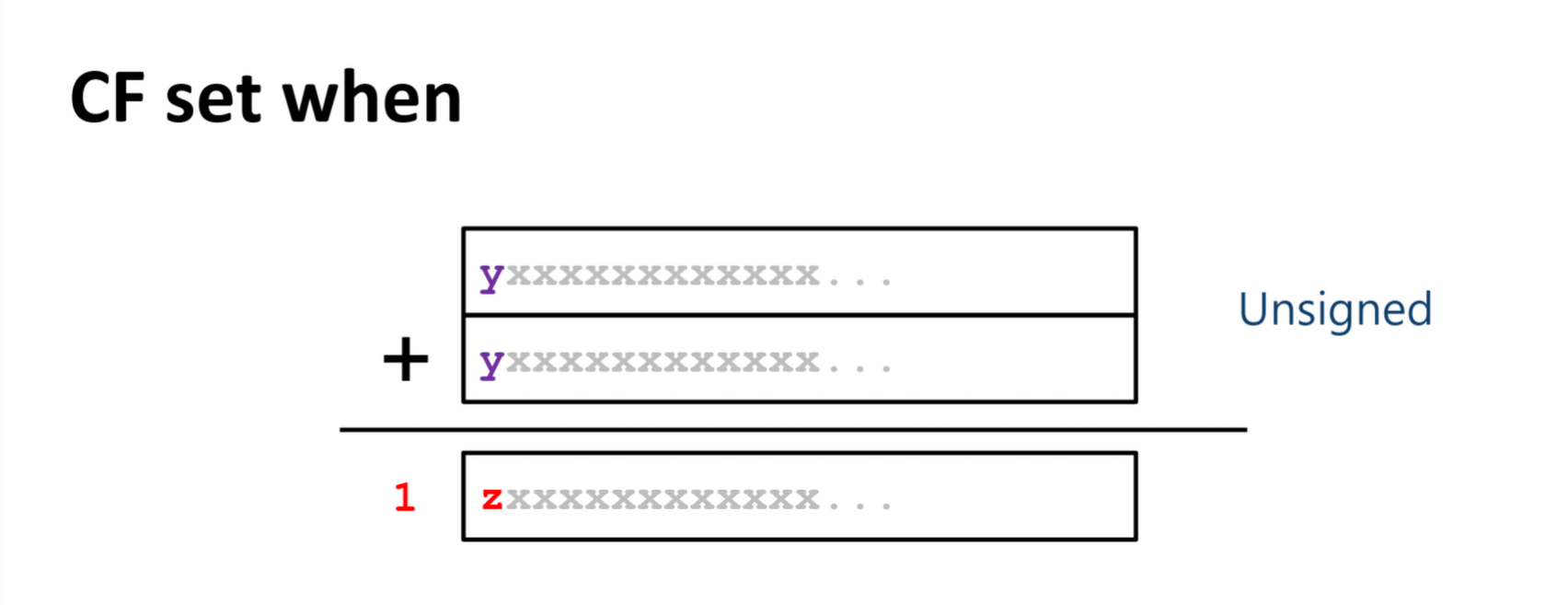
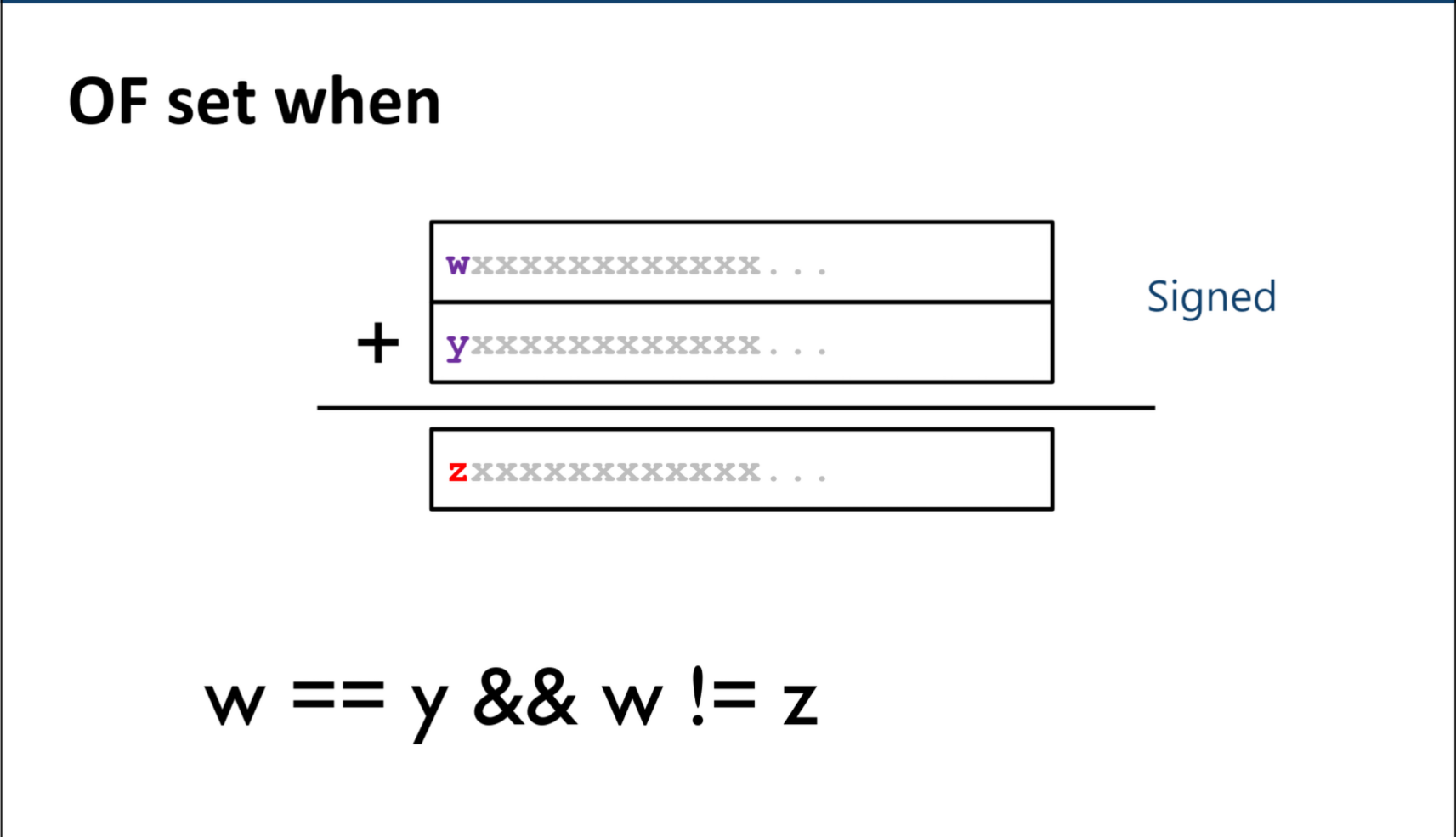
条件码 Condition Codes
Note
以下解释仅仅针对的是加减法,关于乘除的原理,要复杂得多,在计算机组成课程中会对乘除法的硬件原理进行部分讲解。
CF:进位标志,针对无符号数运算设置的;无符号数加减法超过表示范围就会产生进位/借位,此时标志位就会被设置(为1);SF:符号标志,为符号数运算设置的;如果符号数运算后,结果的符号位是1 。ZF:零标志,如果运算结果为0,则设置为1;OF:溢出标志,为符号数运算设置;设加法的两个运算数的符号位是w和y(减法在硬件层面最后也被转化成加法,所以实际是一样的东西;且实际上符号数的减法得到结果永远不可能发生溢出),结果符号位是z:wy同正,得到负数,说明超出表示范围,w != z,setOF;wy同负,得到正数,说明超出表示范围,w != z,setOF;
跳转操作分类
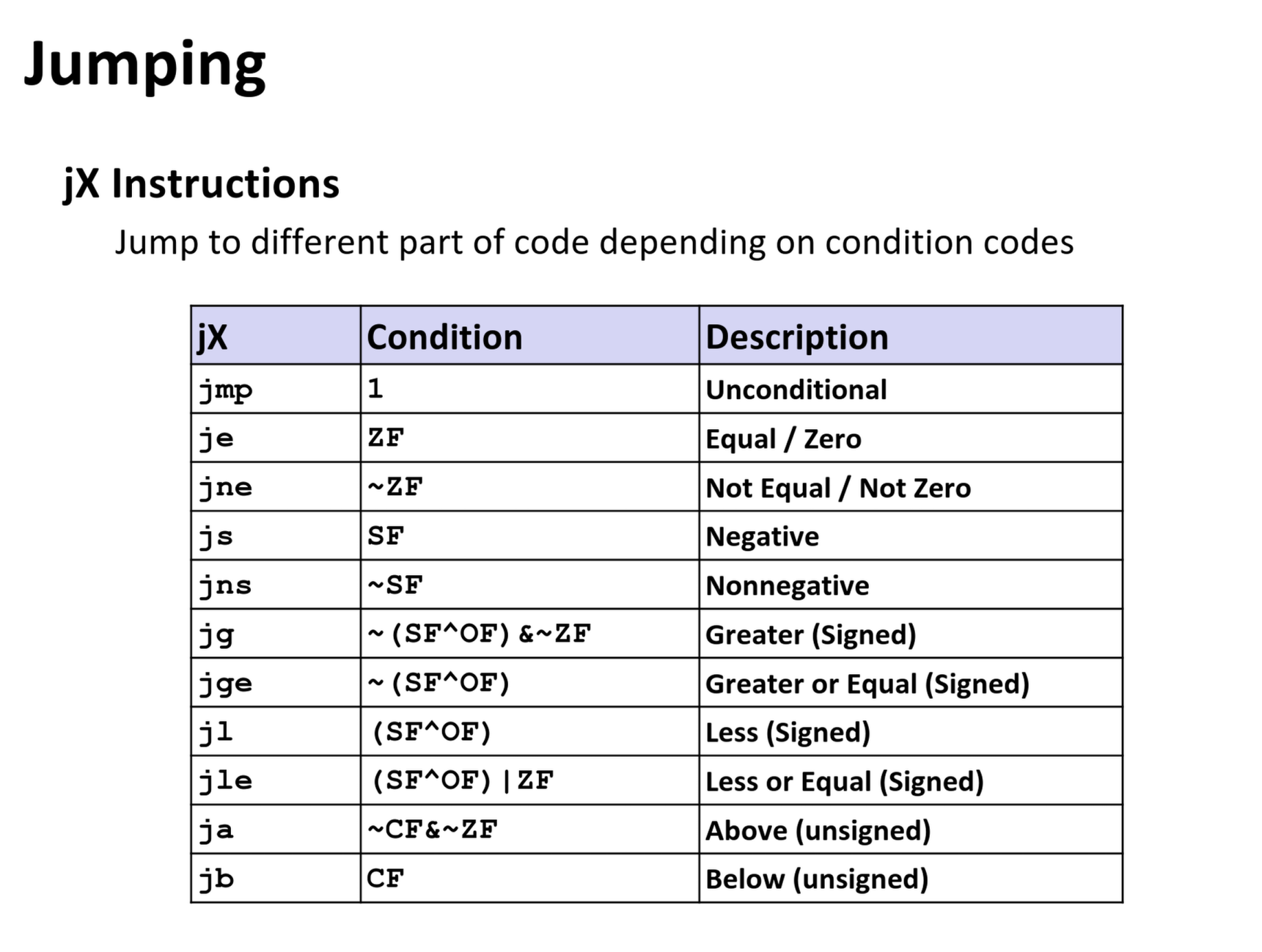

从上面的图中可以看到,不同的跳转命令针对的运算类型都不一样,本题中涉及到的命令是ja,那么对应的设置条件就是~CF&~ZF,那么就是将两个内存单位的数据都当成无符号数进行运算,不发生进位,且结果不为0。所以如果首参是一个负数,则符号位会被看成最高位,数字本身会被视作一个巨大的正数,自然是大于7的数了,所以会触发“爆炸”。
movslq
这个命令可以被拆解为三个部分,分别是mov s lq。
mov是复制操作;s是sign-extend(符号拓展)的意思,也就是在拓展的时候,填充的位要和符号位保持一致;与之相反的是z(zero-extend,零拓展);lq:意思是从l到q,就是说从32位到64位。下面说明数据类型后缀的具体含义。b:Byte,8位;w:Word,1字约定俗成为2B,所以是16位;l:Long,long类型数据占用32位(如C语言);q:Quad,4字的意思,也就是64位。
phase_4:递归函数
1 | 0000000000001727 <func4>: |
快速解题
文档中关于此题给出的关键词是**“递归”**,所以我们可以尝试从这段代码中寻找某个类似于递归函数演进的逻辑,并试着写出它的函数表达式/代码。一旦我们搞清楚了这个递归函数的逻辑,并且找到了初始的入参,就能解决这个问题。
在我看来解决这个问题不一定需要用到调试器,自己用笔写写画画可能是更简单的方法。
主框架:phase_5
phase_5的整体逻辑还是相对易懂的。我们下面分步阐述它的逻辑。
-
使用
sscanf在%rsp + 4和%rsp处存入首参x和二参y,并且通过对返回值的检查限定输入的变量数只能为2 。(from1778to1791) -
if (y - 2 > 2) or (y - 2 < 0): explode_bomb();(from1793to179e)Caution
因为
jbe是无符号数比较,所以负数会被看成一个巨大的正数。 -
调用
func4函数,传参情况为func4(5, y);(from17a3to17ab) -
if x == func4(5, y): return; else explode_bomb()。
可以看到,主框架里唯一和递归函数可能沾边的就是这个func4,所以接下来要分析它的逻辑。
递归函数:func4
我们假设传入该函数的两个参数为x和y,以下分步阐述其逻辑。
if x <= 0: return 0(172b~1732);else if x == 1 : return y(1734~1741);var z = f(x - 1, y) + y(1743~174b);return z + f(x - 2, y)(174f~1760)
这是一个很典型的递归函数的结构:先定义递归出口(遇到特定情况结束递归),然后定义递归逻辑。
总体结构
通过以上的分析,可以尝试写出一个完整的函数逻辑。
1 | int func4(int x, int y){ |
所以,我们如果传入二参4,那么经过计算,func4(5, 4)的值为48 ,所以首参需要填48,也就是48 4。
phase_5:用输入字符串访问数组
1 | 00000000000017d7 <phase_5>: |
快速解题
实验文档对这一阶段给出的提示为,“请关注你的输入和array的转换关系”,那么我们就要从此入手,分析array在哪里,以及分析输入以何种模式来处理这个数组。
从开头的函数string_length我们就能判断出,这次我们需要输入的变量只有一个字符串,并且其长度是6 。然后我们从17f5处代码自带的注释# 3100 <array.0>可以猜测出,放到%rsi中存储的有可能是和数组array有关的一个地址。
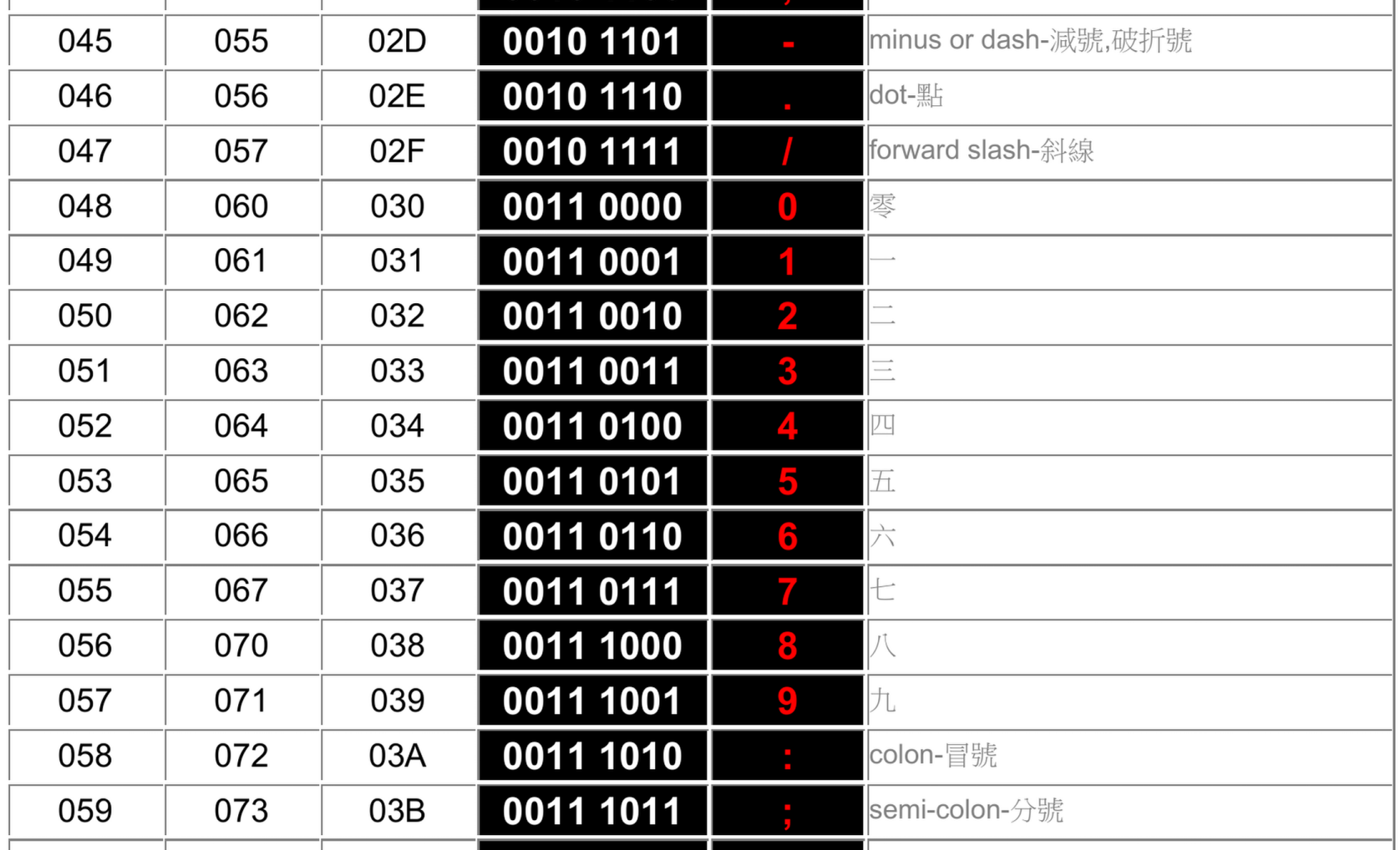
而接下来的两行是对输入字符串当前索引处的字符ASCII码取低4位,而巧合的是,由ASCII码对照表(部分如下图)我们可以观察到,数字0~9的ASCII码低四位恰好是其数字本身的二进制表示,所以这有可能是一个将char型的数字字符转化成对应整型数字的操作。
Note
当然你可以选取任何字符,只要最后截取后四位得到的值能满足题目要求即可。但是选数字是最直观的。
而下面这一条指令add (%rsi,%rdx,4),%ecx,则有点像是 以当前处理的字符对应的索引(或说偏移量)访问数组元素,并将其累加到某个变量中(%ecx) 的操作。所以我们通过GDB验证一下:
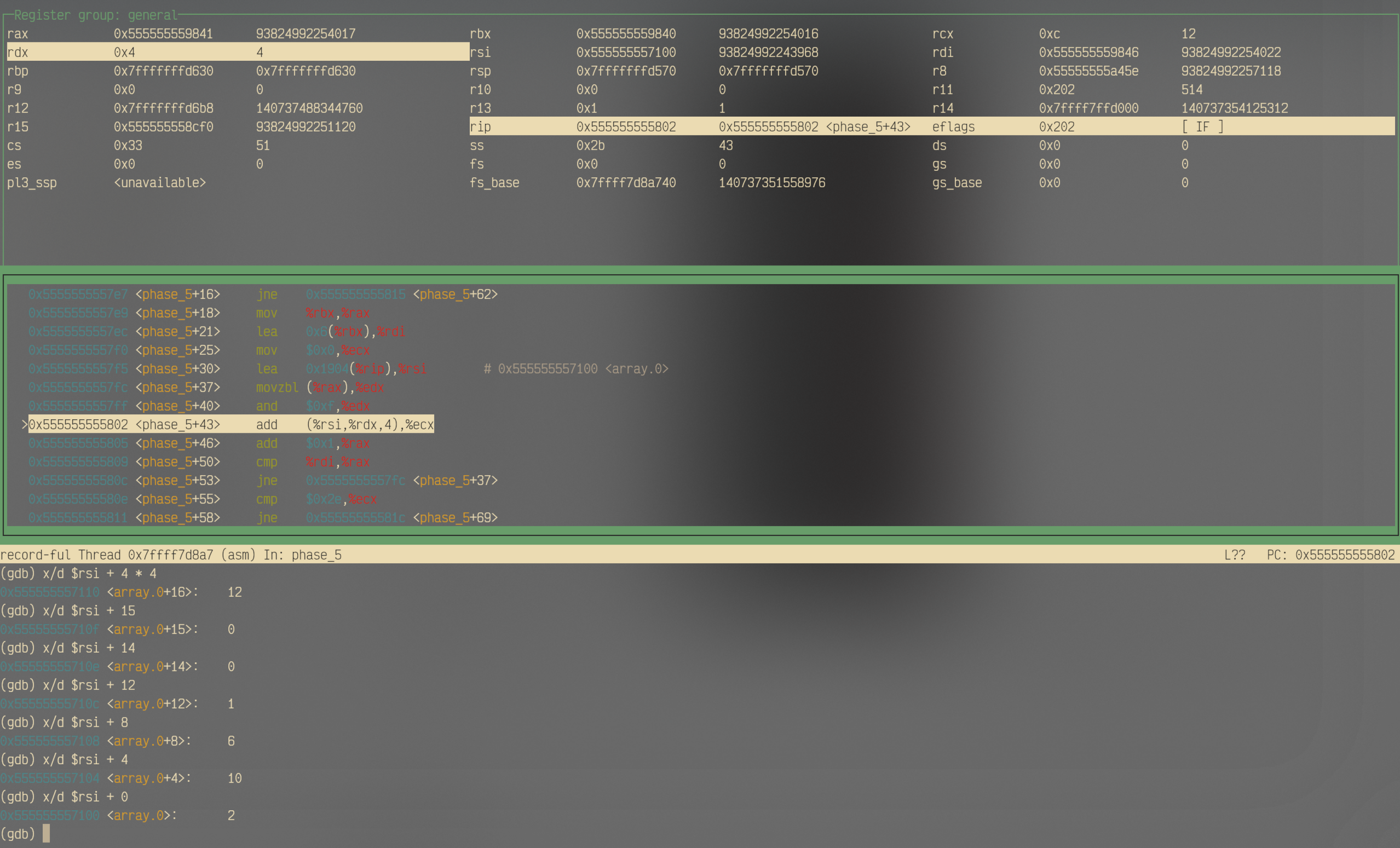
原来真的是每隔四个字节存放一个元素,按照x86-64中int占4字节的惯例,我们合理怀疑%rsi存放了一个整型数组的起始地址。经过调试,可以得出数组的构成如下:
1 | int array[16] = {2, 10, 6, 1, 12, 16, 9, 3, 4, 7, 14, 5, 11, 8, 15, 13}; |
正好对应低四位共16种二进制码。
当累加完当前的数组元素后,%rax像指针一样,递增1字节,指向字符串的第二个字符。而由于%rdi的值已经被提前设置为输入字符串的起始地址向后偏移6字节,我们可以得出,cmp %rdi,%rax(1809)这条指令实际上是判断是否已经遍历完输入的六个字符。在遍历完之后,我们将%ecx的值和0x2e(十进制46)做比较,相等则拆弹成功。
所以观察数组,只要选出的六个元素(可重复)之和为46 ,就可以拆弹。一个可能的答案为444200()。
phase_6:递归
1 | 0000000000001823 <phase_6>: |
快速解题
这一阶段是除了secret_phase之外的最终阶段,代码长度至少是前面阶段的两倍长,用到的寄存器、涉及到的逻辑也比前面的谜题难了一个数量级。如果想要捋清楚,我们需要将这段代码分成几个部分来分析,而分段的依据就是其中一些关键的跳转语句。
阶段1:入口 -> 1899
这部分主要做了两件事情。
- 检查每个输入是否在 1–6 范围内(
sub $0x1后与 5 比较,越界就explode_bomb)。(1888~188b) - 逐个把当前数和它之后所有的数比较,如果有相等的数就
explode_bomb。
所以,可以得出,我们需要给出六个各不相同的整数,取值范围是0~6。
下面总结一下各个寄存器在这段逻辑中的用途,或可有助于阅读这段代码:
rsp:这段逻辑内位置不变化,存储存放六个数字的内存单元首地址;r14:迭代计数器,记录这段逐数比较循环的执行逻辑,过程中取值从1到6(实际循环只有5次,值为6时跳出),指示目前处于第几个循环;r13:辅助比较,存放比较逻辑里遍历数字过程中的基址。r12: